Why Do Cloud Migrations for Broadcast Fail to Reduce Costs?
The pattern tends to look like this: a broadcaster lifts their on-premises architecture, shifts it to AWS ,Azure, OCI or Alibaba, and finds their bills are nearly as high as what they paid before. In some cases, higher.
The issue isn’t the cloud platform. It’s that the underlying architecture was replicated rather than reconsidered.
Traditional playout generates real-time transport streams because SDI requires it: strict timing, no jitter, always-on infrastructure running 24/7 regardless of actual demand. When broadcasters move to cloud with that architecture intact, they replicate the same cost structure: GPU instances running around the clock, 1+1 redundancy on everything, cloud treated as servers in someone else’s data center.
That approach leaves most of the potential savings unrealized.
What Can Reduce Broadcast Cloud Costs Significantly?
The workflows achieving the most meaningful cloud cost reductions typically share a common architectural shift: they reduce dependence on continuous real-time transport models and move more of the workflow toward segmented, file-based processing and delivery models such as HTTP Live Streaming (HLS).
This is less about a single protocol change and more about restructuring how compute, storage, and timing constraints are handled across the entire media pipeline.
It’s a change that sounds straightforward, but it restructures how infrastructure is used:
Shift toward segment-based workflows (e.g., HLS) Moving parts of the delivery chain to segmented formats such as HTTP Live Streaming reduces dependence on strict real-time transport. Content is processed and delivered in discrete segments, enabling more flexible compute scheduling, scaling, and resource utilization.
Relaxation of real-time transport constraints Unlike traditional broadcast transport systems, segmented delivery models reduce sensitivity to network jitter and timing precision. Variability in processing or delivery is absorbed at the segment level rather than directly impacting the continuity of the stream.
Increased use of asynchronous and offline processing Workflows such as packaging, transcoding, highlights generation, and QC can often be executed in batch or near-real-time modes. This enables better utilization of compute resources, allowing infrastructure to scale dynamically rather than remain continuously provisioned.
Reduction in always-on infrastructure requirements By decoupling processing stages and introducing elasticity, systems can reduce reliance on fixed-capacity, 24/7 infrastructure models that are common in traditional broadcast environments. Resources can be scaled up for demand peaks and scaled down when idle.
Built-in storage redundancy and recovery models Cloud object storage inherently provides high durability and redundancy, reducing the need for infrastructure-level duplication. Recovery and failover can often be handled at the application layer, improving operational flexibility and reducing operational overhead.
The Four Phases of a Broadcast Cloud Migration
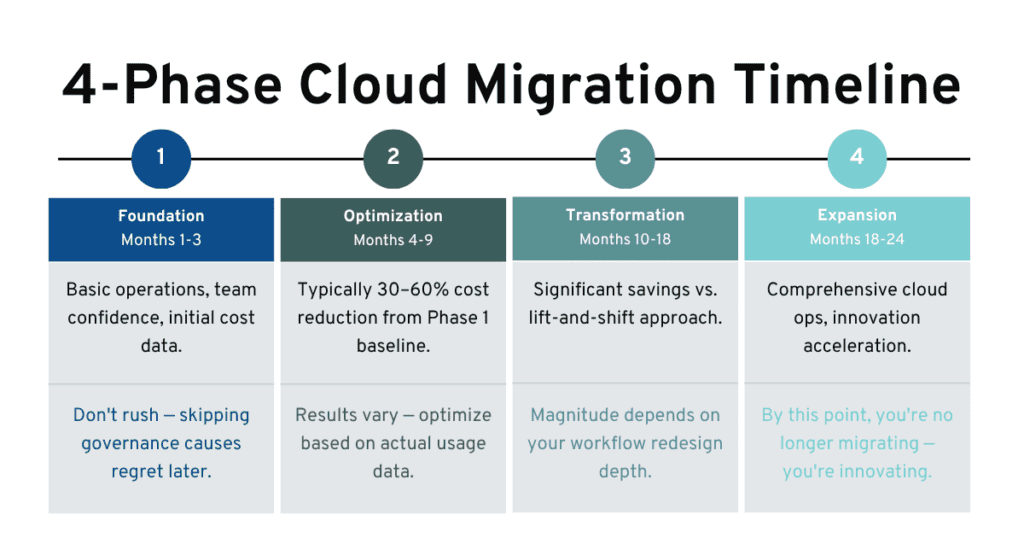
Most cloud migrations move through four identifiable phases. The cost outcomes at each phase are significantly different.
Phase 1: Infrastructure migration. The operation moves into cloud. The architecture proves out in the new environment, and geographic flexibility improves. Costs remain relatively high because this phase is essentially renting cloud infrastructure to do what on-premises infrastructure was already doing.
Phase 2: Optimization. Serverless compute is introduced where it fits. Spot instances handle bursty workloads. Redundancy becomes dynamic rather than static. Costs typically drop significantly from the Phase 1 baseline. This is where many operations stop, and it’s a reasonable outcome.
Phases 3 & 4: Transformation and Expansion. The underlying workflow is reconsidered, not just optimized. Offline rendering, static file serving, and elimination of entire infrastructure categories become possible. Dramatic cost reductions are achievable at this phase. Few operations reach it because it requires rethinking what playout means operationally, not just technically.
What Are the Main Objections to Broadcast Cloud Migration?
Three concerns come up consistently. Each has a practical response.
“Bandwidth costs will be prohibitive.” This tends to hold when content moves between cloud and on-premises repeatedly. When workflows stay cloud-end-to-end and use efficient compression, the calculation changes. JPEG XS delivers a significant bandwidth reduction with sub-millisecond latency.
“Latency requirements can’t be met in cloud.” For viewer-facing distribution, this is generally not a limiting factor, as OTT workflows (e.g., HTTP Live Streaming) already operate with inherent latency of several seconds.
For live production workflows, latency-sensitive use cases are typically addressed through a combination of:
- optimized cloud regions
- edge deployment models
- and specialized low-latency transport and processing architectures
For example, services such as AWS Wavelength or Azure edge offerings can bring compute closer to contribution sources, reducing network round-trip latency for selected workloads.
However, ultra-low-latency production still depends heavily on workflow design, not just infrastructure location.
“Integration with legacy systems is too complex.” Sometimes it is, particularly with legacy traffic systems using proprietary protocols. The practical approach is to start with lower-risk integrations, like file-based graphics, REST APIs, and work toward more complex system dependencies once the simpler integrations are stable.
How Should Broadcasters Approach a Cloud Migration?
For most broadcast operations, the progression is: prove viability in cloud first, optimize incrementally, and then evaluate whether a deeper workflow redesign is worth pursuing. Not every operation will reach Phase 3 (workflow redesign), and not every operation needs to. However, organizations that do reach this stage often unlock significantly greater efficiency gains than are typically achieved through infrastructure migration and optimization alone.
The decision to pursue deeper redesign is usually driven not only by cost considerations, but also by factors such as agility, scalability, operational complexity, and the need to support new content formats or distribution models.
Getting Started: Evaluating Your Cloud Migration Potential
A structured assessment covers four areas:
- Which workflows are viable candidates for cloud transformation versus simple migration
- Where bandwidth and latency constraints are real versus assumed
- What cost outcomes look realistic at each migration phase given your specific infrastructure
- What a phased kickoff looks like operationally, not just technically
The answers differ significantly by facility size, workload type, and existing infrastructure. Starting with real data from your environment is more reliable than benchmarking against industry averages.

Golan Simani | Director of Cloud and Technical Operations | TAG Video Systems
Golan Simani is Director of Cloud and Tech Operations at TAG Video Systems, where he leads product development on AWS, Azure, and GCP, manages technical account relationships with tier 1 broadcasters, and guides organizations through cloud migration POCs and RFP processes.
The most common reason is architectural replication: lifting on-premises infrastructure design into cloud without changing the underlying approach. Transport stream-based workflows running 24/7 in cloud carry similar cost structures to on-premises. Meaningful savings typically require changing how workloads are designed, not just where they run.
Transport streams require always-on infrastructure with strict timing constraints, a model that works well for SDI but generates continuous compute costs in cloud. HLS delivers content as files, which allows for offline rendering, idle infrastructure between processing jobs, and simpler redundancy through standard cloud storage.
It depends heavily on the migration phase and architectural approach. Optimization of an existing cloud deployment typically yields significant cost reduction. Workflow redesign, moving to file-based playout, offline rendering, and static delivery, can yield dramatic reductions. Both outcomes vary based on workload type, channel count, and redundancy requirements.
A practical sequence: prove the architecture works in cloud at small scale, optimize infrastructure usage (spot instances, serverless, dynamic redundancy), then evaluate whether a full workflow redesign is warranted. The third phase requires more organizational change than the first two and isn't the right starting point for most operations.
How does JPEG XS reduce bandwidth costs in cloud broadcast? JPEG XS is a low-latency compression format that reduces bandwidth requirements significantly compared to uncompressed or lightly compressed video. In cloud environments where bandwidth costs are calculated by volume, this can make UHD and multi-camera workflows materially more cost-effective to run.
- Typical compression: 6:1 to 10:1
- 4K becomes ~1–2 Gbps instead of 12 Gbps
- 80–90% less bandwidth